

In this white paper, we outline why automation is necessary for AI/ML Engineering team and Zenlab’s solutions to solve critical challenges that AI/ML Engineering teams faces today. If you are interested in a demo, please reach out to shirish@zenlabs.com for an overview and a demo.
Introduction
As AI and ML is getting pervasive into our technology landscape, there is a huge benefit in getting your Data Scientists to focus on models rather than working on Data Engineering or worse wait on Data Engineers.
There are many different acronyms – DataOps, Data Engineering, Feature Engineering, and even MLOps to indicate improvement in process and engineering. For building and deploying ML to production at scale, a key is to bring DevOps automation that is the Continuous Integration (CI) and Continuous Deployment (CD) to ML world.
Many organization are doing or in the process of bringing automation to AI/ML Engineering. However, even when you have your shiny DevOps CI/CD pipeline built and automate the whole process, they still face tremendous challenge with Data. The paper will provide a DevOps solution to the ML engineering problems.
As Data is New OIL, many organizations have data in your production system that are supporting business critical system such that those data may not be available as ML Engineering may overload the database in a way the critical system may not be able to function; thus, preventing ML Engineering teams at the mercy of the availability of the data. This is the big conundrum for ML Engineering team as they exist purely due to data; however, not having the actual data, they are unable to function properly.
The architecture and design presented in this paper, are from our experiences in implementing ML projects in organization that have large data and heavy regulations as well as based on our own application development effort.
In this paper, we will outline challenges facing ML projects and provide Zenlab’s solution in Data Engineering with our proprietary toolset and ML Engineering automation with DevOps.
Putting Data Science in Perspective
Data Science projects work may be broken into two major parts. They are Data Engineering and Data Science.
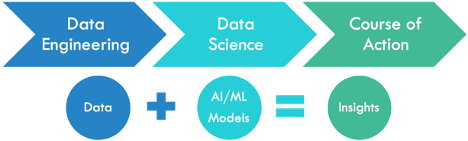
Data Engineering is about
- Sourcing the data from different databases inside your enterprise or outside your enterprise
- Doing ETL that includes cleaning/cleansing of data. At this point you may also sanitize/anonymize such that data is secured while working on Data Science
- Doing feature engineering to extract relevant information from data. This may fall into data science realm as one of the value data scientist/analyst bring is analyzing the data and make sense out of it.
Data Science is about understanding and analyzing the data and then model it so that we can draw insights into business. It is about
- Creating hypothesis on business problems
- Developing models to testing hypothesis either to prove or dis-prove
- Discover new knowledge on the business
Data Scientists develop features and train models. Once they get access to the data, they often spend weeks cleaning and then turning it into features and labels. They then develop and train models, and then evaluate them. They repeat this process several times until they have a model that can be used to test the hypothesis.
ML Engineering
Developing and releasing quality software is hard. If there is no automated process, it is downright expensive and increases risk to business due to unseen failures.
For a software engineer, being able to write, test, and quickly deploy and perform tests (integration, performance, vulnerability) are very important to have a successful non-eventful release. An Organization must develop an engineering cultural practices that recognizes continuous – building, testing, and deployment practices. To achieve such culture, engineers must adhere to writing test codes that covers most test scenarios as well as design for automation.
Data Science Software development is even harder if there is no engineering culture of continuous – build, test, and deploy practices. Following flow shows a typical ML process where there is Data Pipeline (ETL) and Training Model is part of process. A data scientist is dependent on Data Engineer to implement ETL and operationalize it before a model can be operationalized. Similarly, once the training is complete, the data scientist is dependent of ML Engineer to operationalize his model. Even before operationalizing it, the Data Scientist is dependent on Product team to integrate with the current or future service offering. Those intricate interaction among various team members if they are in the same team otherwise, the interaction will be with various teams which bring much more complexity not only in software engineering but also team and inter personal interaction.
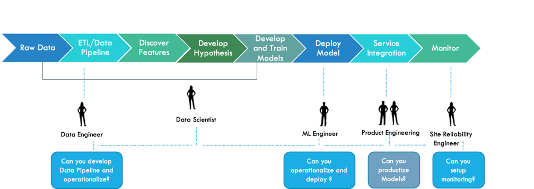
This where DevOps plays an integral role in bringing engineering culture of continuous build, test, and deploy practices. Automating model training and deployment will hugely save time to market for operationalizing model. Thus, allowing Data Scientists to focus on their core competencies rather than coordinating efforts to deploy their model into production.
General DevOps Definition
DevOps is an approach and collection of best practices set within the context of an organization to achieve its business goals through technology. An Engineering Culture and Practice in an organization allows software engineers to achieve incremental feature changes through a Continuous Integration/Delivery (CI/CD) pipelines. A typical pipeline runs unit tests, builds the software artifacts, runs integration tests, and eventually rolls out the change to production in a controlled fashion or stages the release for distribution based on the organization’s need.
Is DevOps a necessity?
Under Engineering Practice, software engineers are empowered to have responsibility developing high quality products through use of test driven development and other engineering practices that enable them to build features in agile fashion.
Engineering teams are enabled to rapidly iterate through features. These features may be empirically tested with customers such that only customer impacting features are productized. Such a process will improve performance to a team to delivery features that impact business goals. Many organizations have been practicing the process to achieve their business goals.
Can we apply DevOps philosophy to ML Engineering?
The sort answer is yes; however, AI/ML teams faces unforeseen challenges that a standard software engineering team normally do not encounter. That is DATA. Data Science a.k.a AI/ML Engineering team cannot function without DATA. Their existence is based on DATA. Of course, software practice apply to them and they also use them. However, if the team does not have access to DATA, their work will be in vain.
An organization may have the best DevOps implemented with fully automated process to get into production quickly that build your model and deploy into production in no time; but if the team does not have data to build and test their AI/ML models, those model will be un-predictive and useless in production with no value to business.
What challenges are ML Engineering team facing?
Key success factor that defines a ML Engineering team is that they have access to Data and then they have automated their software engineering to achieve agility and efficiency in delivering value to the business. A ML Engineering team faces following challenges in two broad category.
- DataOps – Data Engineering
- Data collection from different sources and extraction
- Data pipelines that primes for analysis and models
- Data Science
- Develop features and models
- Train Models
- Discover new features
- Data: Not able to get the production data “quickly” for analysis and feature engineering
These challenges make getting machine learning (ML) into production a difficult and painful process. In comparison with classical software development and deployment, AI/ML engineering and deployment is an order of magnitude harder. As a result of this challenges, most AI/ML models never see the light of production-day. Thus, due these challenges, many organizations fail to capture benefits of ML quickly to capitalize on their data and provide their customer with next generation experiences.
Zenlabs’ Solution
At Zenlabs, we have developed solution for Data Engineering and ML Engineering through the use of DevOps platform. Please contact us for detail demo and solutions.
